Integration of Jupyter Notebooks into Alpine Chorus, making the popular interactive documents first-class citizens in the data science platform.

About Data Science Notebooks
Interactive notebooks are a fascinating tool for anyone who works and learns by empirical inquiry.
An example of Literate Programming, notebooks allow a person to write and develop in a process that is like having a conversation with the subject matter, iterating in the order of their thoughts, and organically generating a record of their process.
This is akin to stream-of-consciousness thinking and resembles the creative process itself.
For the data scientist, data analyst, or anyone working with data — big and small — interactive notebooks can be used for discovery, feature development, transformation, visualization, and model running. They are equally well-suited to reusable procedures and shared code routines, such as data cleaning functions that are used repeatedly by a team.
Their popularity in data science made them a frequent user request for support in Chorus.
Designing the Integration With Chorus
All aspects of the integration were considered from a user-experience-centric point of view when incorporating notebooks into Alpine Chorus.
At the system level, the requirement was defined that there must be isolated sandboxing and authentication/authorization for individual users, so that notebooks would maintain existing access restrictions and data security.
For the visible aspects of the integration, new Chorus abilities were added to make notebooks equivalent to the existing data science collaborative tools:
- Create a new notebook
- Import (upload) an existing notebook
- Copy a notebook to another project
- Comment and tag a notebook
- Search for a notebook by name or content
Keep the Existing Good
Once a notebook was opened, an important design requirement was that the general user experience of Jupyter notebooks, such as composing and editing a notebook, should not change. This ensured that using notebooks in Alpine Chorus would be familiar to people who have already used stand-alone notebooks, while people new to the tool could learn using the existing community resources (documentation, example notebooks, StackExchange, etc.). Therefore, the core editing, viewing, and running behaviors were not changed.
Changes were made, nevertheless, to improve the user experience and to benefit the user. Features were removed, and features were added.
Using a notebook within the Chorus platform, rather than running it locally on the data scientist’s own computer (as is the most common case), means that managing kernels manually is no longer relevant. So that function was removed. In addition, “checkpoints” were replaced with the existing Chorus file versioning behavior for a consistent experience in the Alpine context.
Add More Good
Add Data to a Notebook
In Chorus, data sources (e.g. a database, or a Hadoop cluster) are added to the application as source connections for data used when creating analytics. These sources can be shared by everyone, or limited to the specific permissions of the user. Once the data source is made available, users can then browse the source and identify specific data collections — called datasets — to be attached to a project workspace, the team environment where the collaboration and data science work happens. Workspaces are also where notebooks are available.
To make a simple user experience, a new feature was designed that lets a user easily add the workspace’s data sets to the current notebook. The existing notebook menu was augmented with a new “Data” section, and the “Import Dataset” action was made available in this menu.
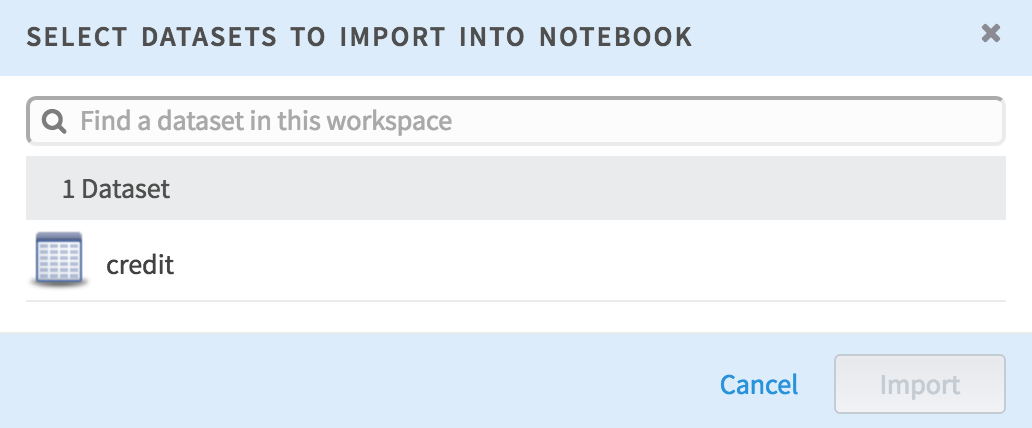
This provides the means to select from the datasets already available to the current workspace. Choose a dataset, and Chorus automatically generates the data frame in the notebook.
Notebooks and Recurring Jobs
Like software development, an interactive notebook goes through a lifecycle. In its finished state, the notebook might be a data transformation process or an analytic model for business questions. If that model needs to be executed repeatedly, the regular way of running a notebook is burdensome and unwieldy.
To solve this problem, the Chorus job functionality was extended to include notebooks. A job, an existing feature in the platform, lets a user create a sequence of tasks and run them either on-demand or on a schedule. Now, a notebook could be simply be included as another task.
